Covariate search
The Covariate search section allows users to systematically test potential covariates for inclusion in their model, helping reduce unexplained variability and improving the model's interpretability and predictive performance.
📌 Note: Before working in this section, ensure that the project has already been fitted or that results from a previous fit have been loaded in the Task section.
Once this is done, the Covariate search section in NLME becomes available to be used:
Begin by selecting the parameters to which covariates will be applied. This is done in the Select parameters dropdown. Once selected, click the  button to proceed. You may add multiple covariates, repeating this process as needed.
button to proceed. You may add multiple covariates, repeating this process as needed.
1. Covariate specification
After clicking , specify the covariate details in the configuration panel:
-
Covariate: Choose the column from your dataset to test as a covariate.
-
Covariate type: Specify whether the covariate is Continuous or Categorical.
If Continuous
-
Select the Function to define how the covariate influences the parameter:
- Linear (lin): $$\theta_i = \theta_{ref} \cdot (1+\beta \cdot (x_i-x_{ref}))$$ A direct linear relationship between the covariate and the parameter.
- Log-linear (loglin): $$\theta_i = \theta_{ref} \cdot \exp(\beta \cdot (x_i-x_{ref}))$$ A multiplicative effect, useful when the effect increases or decreases exponentially.
- Power $$\theta_i = \theta_{ref} \cdot \left( \frac{x_i}{x_{ref}} \right) ^\beta $$ A flexible model that can capture nonlinear proportional effects, often used in allometric scaling.
-
Also select a Transformation (either median or mean), which sets the reference value used in the function.
If Categorical
- Define the Reference category, which acts as the baseline for comparison across levels.
-
Next, provide an Initial value — this is the starting estimate for the covariate effect and will be used during model fitting. You can also specify any Ignored parameters, which are parameters selected earlier but that should not be linked to this covariate.
When you're satisfied with the covariate setup, click  to confirm it. If adjustments are needed later, click
to confirm it. If adjustments are needed later, click  , make the necessary changes, and click again. To remove a covariate entirely, use the
, make the necessary changes, and click again. To remove a covariate entirely, use the  button.
button.

2. Covariate search options and results
Once the covariate specification is complete, the Covariate search options section allows you to configure how the covariate testing will be executed.
-
Methodology: Currently, the only available method is SCM (Stepwise Covariate Modeling). This methodology consists of two phases:
- Forward selection, where covariates are added one by one based on statistical significance (typically using a predefined p-value threshold).
- Backward elimination, where covariates already included are systematically removed if they no longer meet the criteria when combined with others.
SCM helps in building a parsimonious model by balancing fit improvement with complexity.
-
RSE penalization: If selected, this option activates a check for parameter identifiability by evaluating the Relative Standard Error (RSE) of estimated parameters. When this option is enabled, the RSE threshold (%) input appears.
- The threshold defines the maximum acceptable RSE for a parameter to be considered identifiable.
- By default, this threshold is set to 50%.
-
Forward selection p-value and Backward elimination p-value: These fields allow you to define separate p-value thresholds for each phase of the SCM process. These thresholds determine the statistical criteria for including or removing covariates during the search.

After all search options have been specified, click the  button to begin the process.
button to begin the process.
Once the covariate search is complete, two result tables are displayed: Forward Selection Table
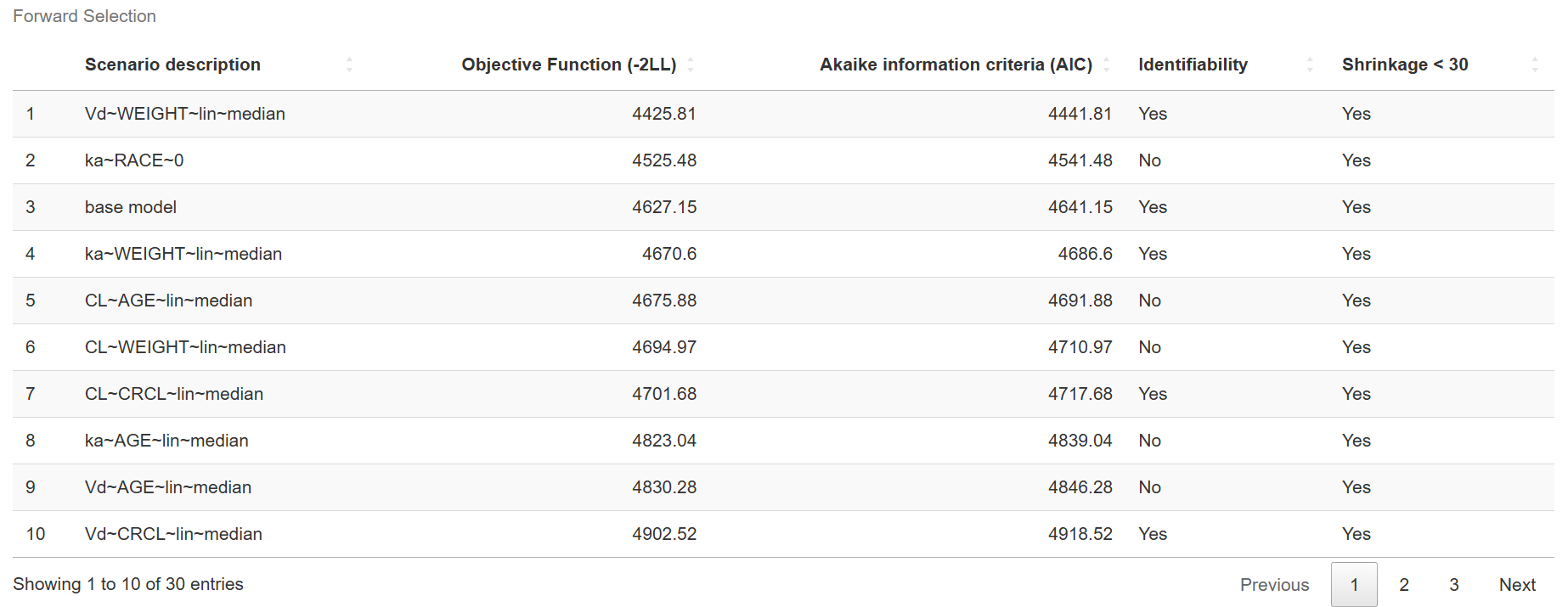
and Backward Elimination Table

Each table includes the following columns:
- Scenario description: A summary of the covariate tested and the parameter(s) to which it was applied.
- Objective Function (-2LL): The -2 log-likelihood value of the model with the specified covariate scenario. Lower values indicate better model fit.
- AIC: Akaike Information Criterion. A model selection criterion that balances model fit with complexity. Lower AIC values are preferred.
- Identifiability: Indicates whether all parameters in the model meet the identifiability criteria based on the selected RSE threshold.
- Shrinkage < 30: A check for statistical shrinkage, indicating whether it remains below a 30% threshold—a common guideline for reliable random effect estimates.
If you've previously performed a covariate search and wish to revisit the results, simply click the  button. The forward and backward tables from the prior search will be reloaded and displayed in the same format.
button. The forward and backward tables from the prior search will be reloaded and displayed in the same format.
After completing the Covariate search process and reviewing the resulting models from forward and backward selection, you can determine whether any covariate effects should be retained in your final model. From here, you may proceed to re-evaluate model diagnostics in the GoF plots section, or move forward to simulate different dosing or response scenarios using the refined model in the Simulations section.