Data initialization
On this tab, the dataset is uploaded for subsequent Exposure-response analysis (ER analysis).
ER analysis evaluates the relationship between drug exposure (e.g., AUC, Cmax) and clinical response (e.g., efficacy or safety outcomes). It helps determine whether higher or lower drug exposures lead to different probabilities of a desired effect or adverse event.
Exposure-response dataset (ER dataset) structure should correspond CDISC standards [1].
The dataset must include two types of variables used for analysis: independent variables (predictors) such as exposure metrics and covariates, and dependent variables — response metrics (endpoints).
A single dataset can contain multiple types of responses. The response type is identified in the PARAMCD column, while the values of the dependent variable are stored in the AVAL column.
Exposure metrics and covariates are stored in separate columns with appropriate names (e.g. CAVESS, CMINFC, AGE).
Work on the Data initialization tab begins with selecting a dataset for exposure-response analysis. To do this, click button  .
.
In the opened window, select a csv file from the directory on the server. It can be a file with a dataset generated when working on the Dataset generation tab, or another dataset.
After the file with dataset is loaded, it appears in the preview on the right side of the screen.
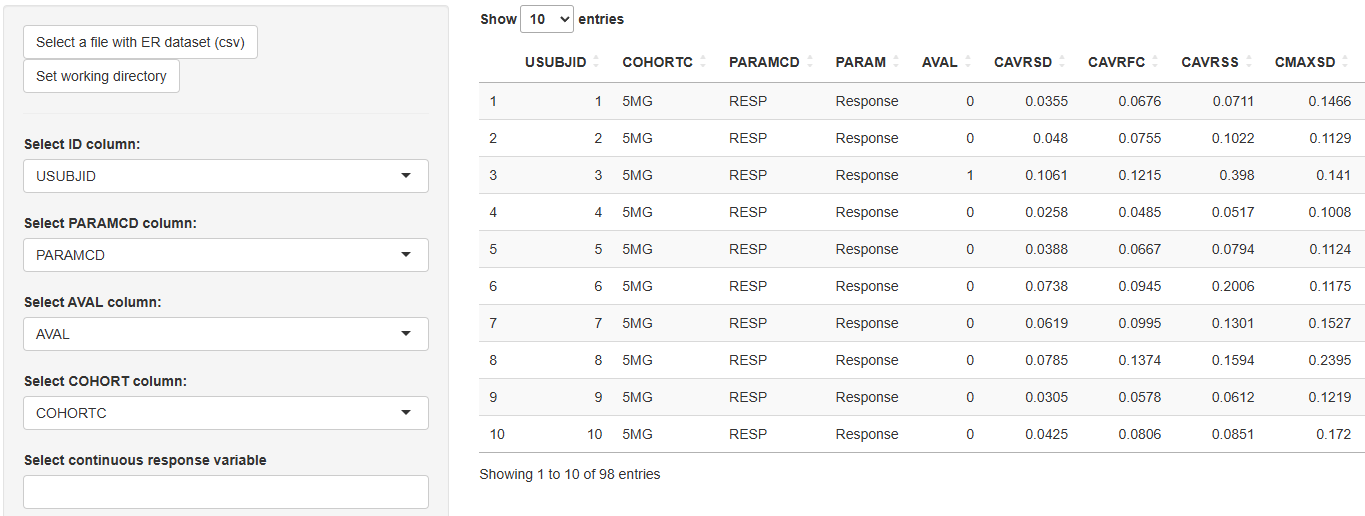
Then one should select names of four mandatory columns from dropout lists:
- Select ID column– the name of the column with the Subject Identificator (e.g.
ID,USUBJID). - Select PARAMCD column – the name of the column with the Parameter Code (
PARAMCD). - Select AVAL column – the name of the column with the Analysis Value (
AVAL). - Select COHORT column – the name of the column with the Cohort values (e.g.
DOSE,TRTP).
In the next block of drop-down lists, one can select the names of the response metric, exposure metrics and covariates that will be included in the analysis:
-
Select continuous response variables - the names of the variables from the
PARAMCDcolumn (for further work in the Continuous section). -
Select binary response variables - the names of the variables from the
PARAMCDcolumn (for further work in the Binary section). -
Select exposure variables - the names of all ER dataset columns.
-
Select continuous covariates - the names of all ER dataset columns.
-
Select categorical covariates - the names of all ER dataset columns.
 button - select a working directory - a folder on the server in which the results of the further analysis will be saved. It could be existing folder or one can create a new one. Selecting a directory is mandatory.
button - select a working directory - a folder on the server in which the results of the further analysis will be saved. It could be existing folder or one can create a new one. Selecting a directory is mandatory.
After all the required fields are filled in, click  . If the working directory and required fields are selected, the message “Dataset successfully initialized” will appear.
. If the working directory and required fields are selected, the message “Dataset successfully initialized” will appear.
If the working directory or some required fields are not selected, a warning will appear.
After successful initialization of the dataset, one can proceed to analysis in the Binary or Continuous sections.