Data
The Data section is the starting point for preparing your dataset for model-based analysis. It allows you to upload, explore, and structure your data by selecting key variables such as ID, time, and dependent values. You can also create or remove columns, filter the dataset, and classify covariates as continuous, categorical, or time-varying. These preparatory steps ensure your dataset is properly organized for further analysis and quality checks within the Data Management module.
To begin working with this module, load a dataset into the environment by clicking the  button. The environment supports datasets in
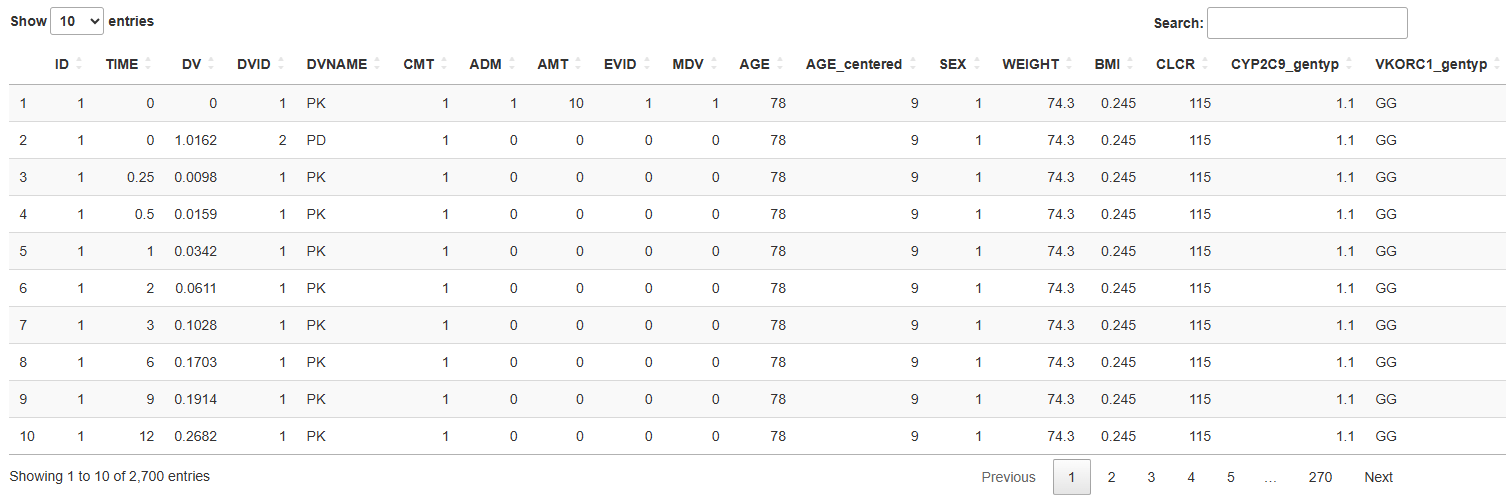
button. The environment supports datasets in .csv format. Once uploaded, the dataset will be displayed in the main panel on the right side of the screen:
Before proceeding, it is recommended to define the directory where you wish to save all outputs generated during this session. This can be done by clicking the  button. If this step is skipped, you will be prompted to select a directory the first time you attempt to save any results. Setting the directory at this stage ensures a smoother workflow throughout the module.
button. If this step is skipped, you will be prompted to select a directory the first time you attempt to save any results. Setting the directory at this stage ensures a smoother workflow throughout the module.
Column Specification
Once the dataset is visible in the main panel, the next step is to identify key structural columns. Use the following dropdown menus to specify:
-
ID Column - dentifies the subject or observational unit.
-
TIME Column - indicates the independent time variable.
-
DV Column - corresponds to the dependent variable (e.g., concentration, biomarker, etc.).
Each dropdown will list the available columns in your dataset, allowing for direct selection.
Data Modification
In this section, you may also perform various data manipulation tasks, including:
-
Adding a new column: Use the "Add Column" window to create a new variable using R syntax. For example:
- To create a character column from a numeric variable:
SEXC = as.character(SEX) - To calculate a summary value like the mean of a column:
BMI_mean = mean(BMI)
If the formula is incorrectly specified, a warning window will inform you of the syntax issue.
- To create a character column from a numeric variable:
-
Removing columns: Use the "Remove one or more columns" window to select and delete any variables that are no longer needed.
-
Filtering the dataset: A filtering option is also available to work with a subset of the original dataset if required.
Covariate Classification
To facilitate downstream tasks, especially quality checks and exploratory analyses, you may specify different types of covariates using the following windows:
-
Select all columns with continuous covariates
-
Select all columns with categorical covariates
-
Select all columns with time-varying covariates, here you specify which columns, previously selected as continuous or categorical covariate, are time-varying.
While specifying these is optional for general dataset work, they are required to activate functionalities in the Quality Check section of the Data Management module.
Dataset Initialization and Saving
Once all necessary specifications and transformations are complete:
-
Click the
 button to apply the selected column designations and any modifications. This step activates access to the subsequent sections of the module.
button to apply the selected column designations and any modifications. This step activates access to the subsequent sections of the module. -
If you've made changes and want to preserve this updated version of the dataset, click the
 button. The file will be saved in the defined directory as a
button. The file will be saved in the defined directory as a .csvfile.
Once you have successfully initialized the dataset, you are ready to proceed to any of the other available sections within the Data Management module: Continuous Data, Covariates, Dosing Events, and Tables. These sections offer specific tools to further exploratory data analysis.
Please note that the Quality Check section will only be accessible if you have specified the covariates (continuous, categorical, or time-varying) in the current section. If no covariates have been defined, this section will remain disabled.